
"delivery?"
That single word, followed by a question mark, appears daily in our support system.
A user somewhere has a problem to solve, but they've expressed it in the briefest possible way.
After analyzing one million support interactions, we discovered that these minimal queries reveal an interesting pattern about how users actually seek help and what it takes to truly assist them.
Turning One Word into Understanding

People don't write perfect questions when they need help. They type things like "delivery?" or "how return product?" and hope for the best. For our support system, understanding these quick questions was tough, especially since what they meant could change completely depending on the industry.
Jay saw an opportunity here. Using AI language models, he built something clever: a system that understands what users are really asking. When someone types "how refund work?", it knows they mean "What is the refund process for purchased items?"
But the real breakthrough came with sector-specific personalization.
In the fashion industry, when a user types "returns?", the system rewrites it to "What is the return policy for unworn clothing items?" That same query in a tech context becomes "How can I return a defective gadget for repair?" This sector-specific understanding ensures users receive the most relevant information for their specific industry context.
The impact was great. Users began independently finding the answers they sought, leading to a 15% increase in self-resolution rates. Average search sessions became shorter which signaled quicker information retrieval. Bounce rates dropped significantly as users consistently found satisfying answers, and the rate of query ambiguity plummeted.
Building Guardrails That Don't Feel Like Walls
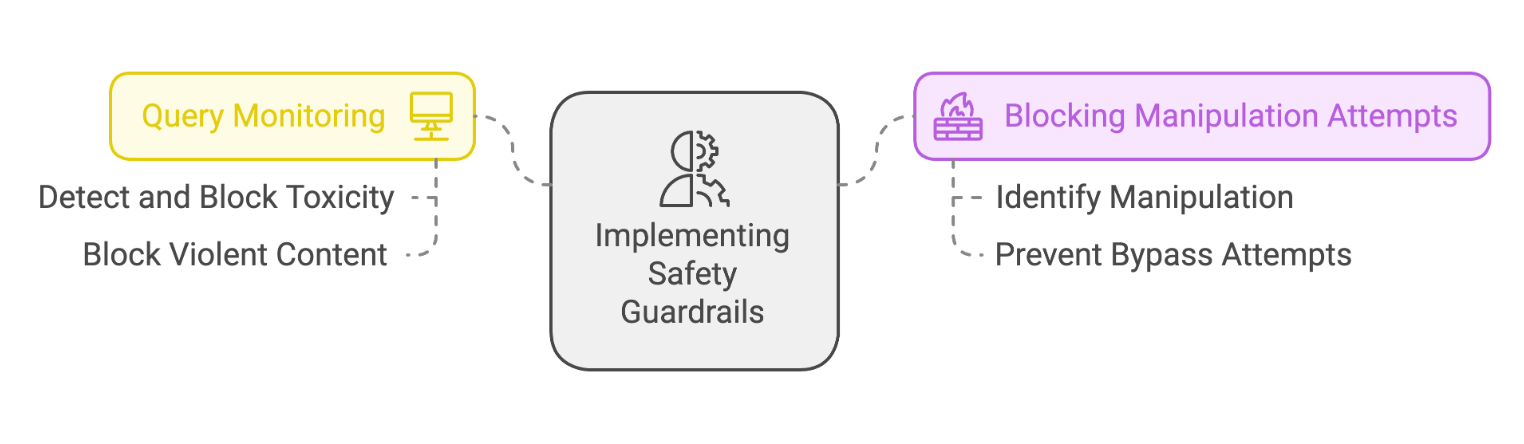
As AI systems grow more powerful, they face challenging security concerns. Users try to find loopholes, either through direct requests for inappropriate content or clever tricks like using translations to bypass filters. Traditional security methods – keyword filters and static rules – proved insufficient for these modern challenges.
Khushi developed a security system that works the way human security teams do. Instead of simple pattern recognition, she built dual-layer protection that understands the deeper meaning behind user interactions. The first layer analyzes incoming requests, examining context and intent alongside keywords. The second layer reviews outgoing responses, ensuring they follow ethical guidelines while still providing valuable information.
Internal tests demonstrated significant progress. The system effectively prevents harmful content creation while reducing successful manipulation attempts – all without sacrificing the natural feel of user interactions.
Finding the Perfect Response Length

Our analysis revealed a critical insight about AI communication: response length significantly impacts how users engage and solve problems. Lengthy responses overwhelm users with unnecessary details that reduce engagement and slow down problem-solving. Conversely, overly brief responses often lack sufficient context, leaving users frustrated with incomplete information.
Like human experts who adapt their explanations to their audience, we created a dynamic response system that adjusts to different domain personas. The system analyzes real examples of human interactions to determine optimal response length based on each domain's typical needs and expectations. Complex topics receive thorough explanations, while simpler ones get concise answers.
The results showed a substantial improvement in AI communication. Users now receive responses with precisely the right amount of detail for their needs, leading to more efficient and satisfying interactions. The system handles complex topics while maintaining clarity, effectively serving diverse information needs across various domains.
Making Intent Actionable
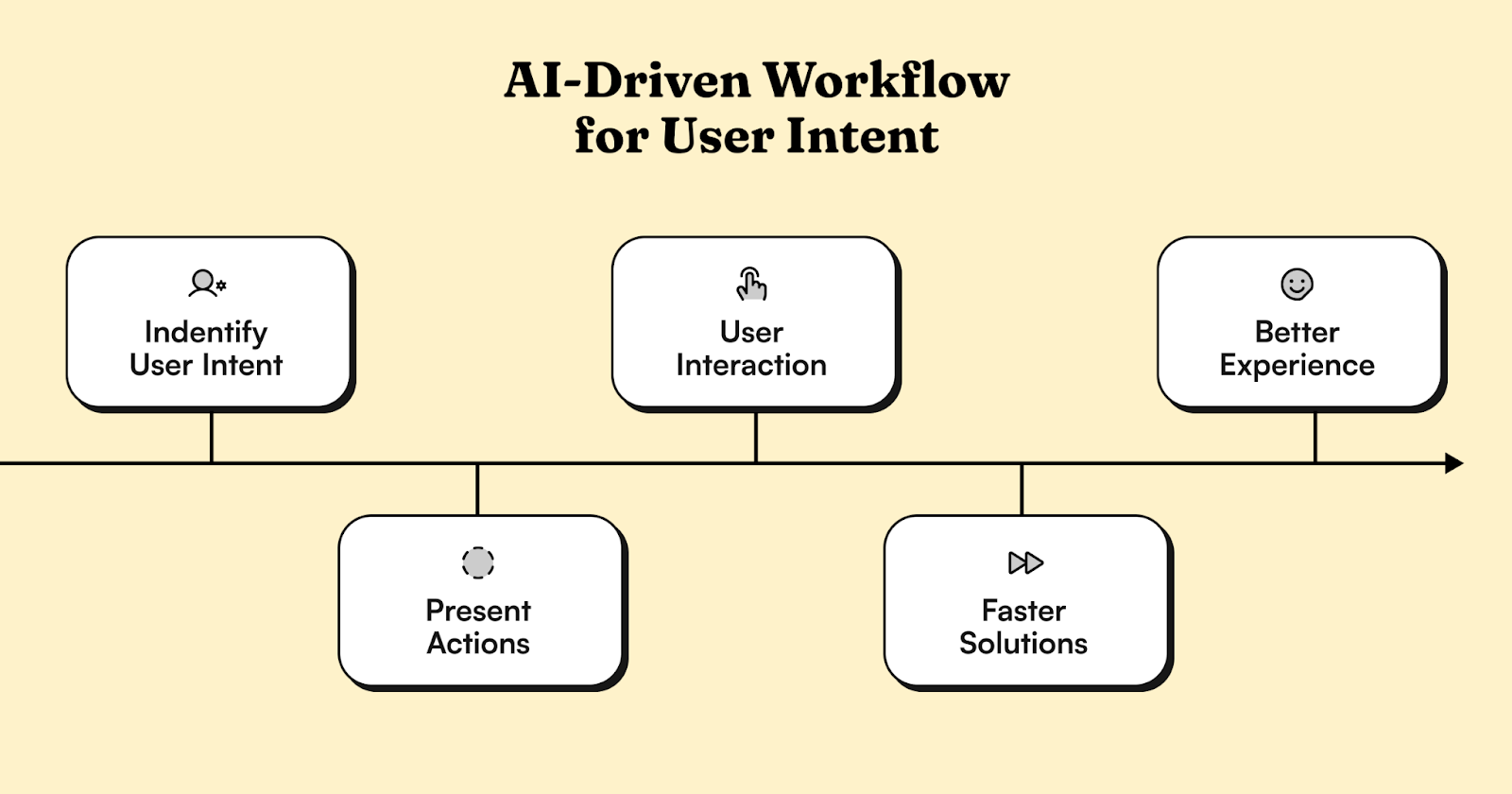
In AI systems, there's often a fundamental disconnect between understanding what users want and helping them take action. When users express a need, they typically get information rather than the ability to act.
We developed a system that maps user intent directly to specific actions. When the AI grasps what a user wants, it not only provides an answer but offers an immediate path forward. For example, instead of just receiving instructions, users get a direct link to view their recent activity.
Ensuring Uninterrupted Service
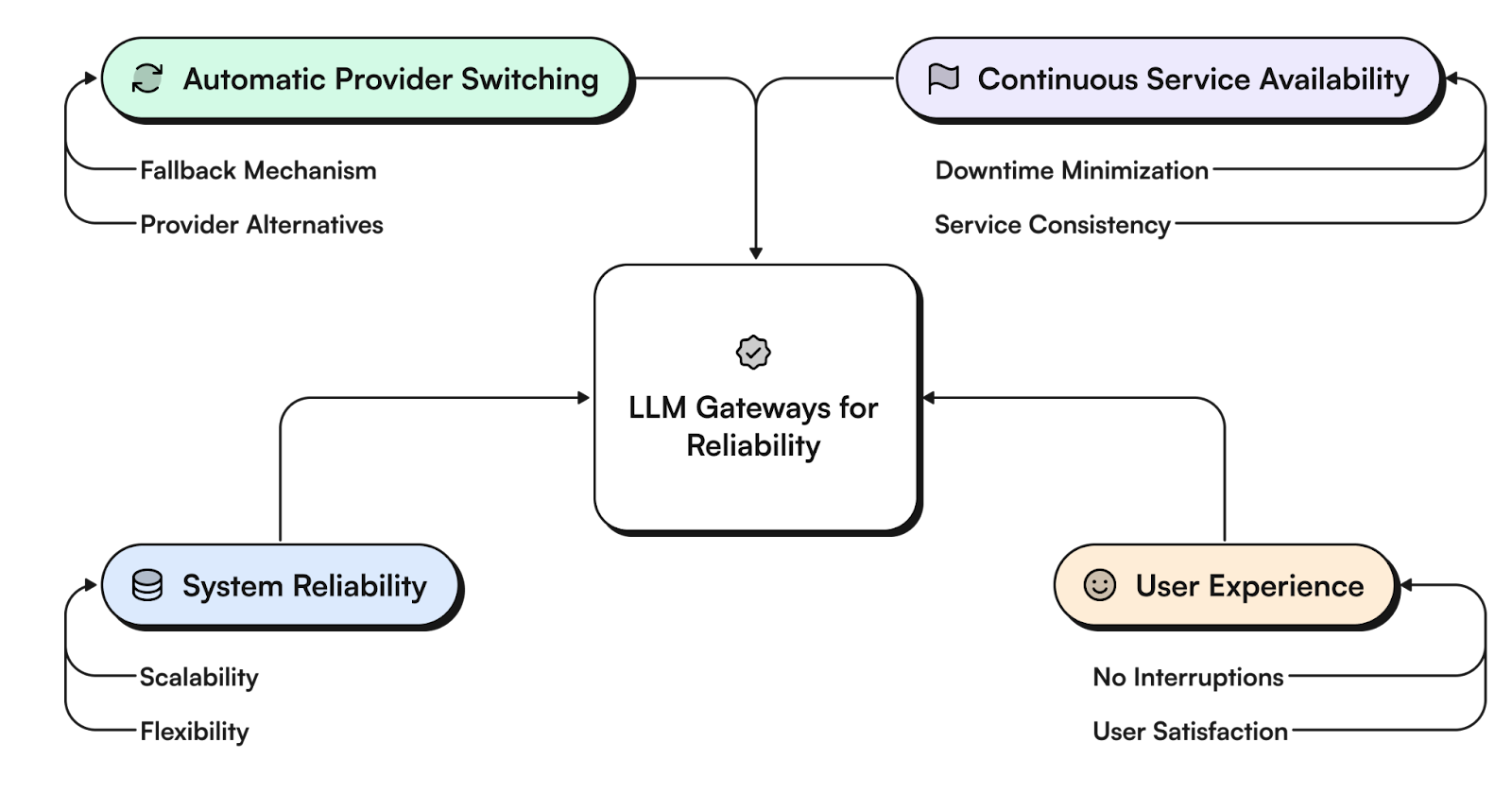
AI systems that rely on a single LLM provider face significant risks. When that provider experiences downtime, performance issues, or other disruptions, the entire system can fail. It's similar to having a business that depends entirely on one supplier. If that supplier has problems, everything grinds to a halt.
Our solution was an intelligent gateway system that acts like a smart traffic controller for LLM requests. It constantly monitors each provider's performance, tracking response times, error rates, and availability. When issues are detected, it makes instant routing decisions based on predefined criteria, seamlessly redirecting traffic to alternative providers.
The switching happens behind the scenes, without any noticeable interruption in service – like a building switching to backup power without the lights flickering. This approach has transformed how we handle provider disruptions, making service interruptions rare and brief when they do occur.
Looking Forward
Our analysis of one million interactions revealed how to make AI support truly helpful. By focusing on metrics that matter – like successful task completion and customer effort scores – we're moving beyond simple automation and chatbots.
The sophisticated engineering behind these capabilities, from LLM gateways to dynamic response optimization, serves a simple goal: making every interaction as helpful as possible.

Daniel is a product and customer experience leader with over a decade of experience solving user experience challenges at scale. As CEO of Brainfish, he is redefining how users interact with technology - championing a new era of proactive, AI-driven support that anticipates user needs before they arise